Mô hình “thần thánh” reCAPTCHA: Biến người dùng Internet thành “nhân công” miễn phí, điện tử hóa 17.600 quyển sách mỗi năm, khiến Google chi 30 triệu USD thâu tóm!
Nếu đã từng trả lời một trong những mẫu reCAPTCHA dưới đây thì xin chúc mừng bạn! Chữ mà bạn nhập giờ đã nằm trong một bài báo của tờ New York Time lừng danh hoặc được lưu trữ tại thư viện lớn nhất thế giới Google Books.
Nội dung nổi bật:
Bối cảnh: Để phòng tránh các cuộc tấn công mạng, chủ website thường sử dụng CAPTCHA như một phương tiện vừa hiệu quả vừa miễn phí.
Kế hoạch: Phát hiện ra sự “lãng phí” của CAPTCHA, Luis von Ahn đã viết nên reCAPTCHA, với nhiệm vụ vừa bảo vệ website, vừa có khả năng dịch văn bản cực kỳ chính xác.
Kết quả: 17.600 quyển sách được số hóa chỉ trong một năm. reCAPTCHA nhanh chóng được Google mua lại sau 2 năm thành lập với giá gần 30 triệu USD!
Captcha và reCaptcha
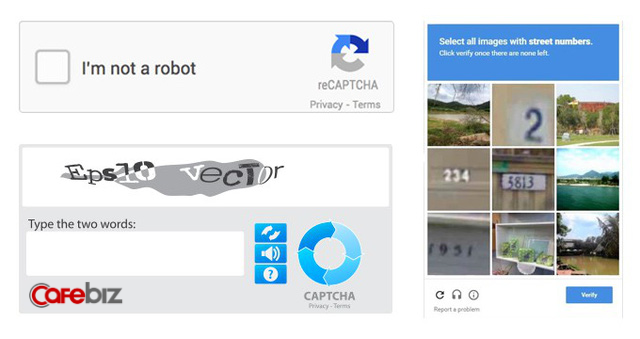
Đã quá quen thuộc với tất cả người dùng Internet, Captcha là một công đoạn phiền toái nhưng cũng dễ dàng vượt qua để chứng minh người dùng thật sự là con người chứ không phải robot.
Thuật ngữ CAPTCHA viết tắt từ Hệ thống Tự động Phân biệt Con người và Máy tính (Completely Automated Public Turing test to tell Computers and Humans Apart), và là đứa con tinh thần của Luis von Ahn từ Đại học Carnegie Mellon.
Captcha được nhiều trang web sử dụng để phòng tránh các cuộc tấn công từ chối dịch vụ hàng loạt hoặc đánh cắp dữ liệu vì sự hiệu quả cũng như giá thành “0 đồng” của mình.
Tuy nhiên, nhà sáng lập Luis nhanh chóng nhận ra rằng, tuy mỗi người chỉ tốn vài giây để hoàn tất một mẫu Captcha, nếu tính tổng cộng số người dùng khổng lồ trên Internet, mỗi ngày có đến hàng trăm ngàn giờ lao động “lãng phí” đang được đổ vào Captcha.
Nhằm tận dụng những giờ lao động quý giá này, Luis cho ra đời reCAPTCHA vào năm 2007.
reCAPTCHA về cơ bản vẫn là một chương trình CAPTCHA thông thường, ngay từ lúc xuất hiện, reCAPTCHA đã chủ động giới thiệu bản thân là một dịch vụ hoàn toàn miễn phí và cực kỳ dễ sử dụng cho các chủ sở hữu website.
Không lâu sau đó, reCAPTCHA được sử dụng rộng rãi và trở thành chương trình phòng vệ mặc định của rất nhiều trang web lớn.
Nhưng ít ai biết được mô hình kinh doanh “thiên tài” đằng sau chương trình miễn phí này.
Hàng chục triệu người dùng Internet đang bị biến thành những “cỗ máy đánh chữ”, đều đặn gõ hàng triệu chữ cái mỗi ngày, điện tử hóa hàng ngàn quyển sách, tạp chí, bài báo từ xa xưa mà không hề hay biết.
reCAPTCHA hoạt động như thế nào?

So với các phần mềm nhận dạng khác, reCAPTCHA yêu cầu người dùng phải nhập 2 chữ cái khác nhau thay vì 1 chữ.
Và cũng không giống các CAPTCHA còn lại, reCAPTCHA không tự động “tạo” những chữ khó nhìn để đánh đố người dùng mà lấy hẳn hình ảnh từ các văn bản vật lý (sách, báo, tờ rơi…) mà phần mềm nhận diện mặt chữ (Optical Character Recognition – OCR) không thể giải quyết được.
Các phần mềm OCR luôn được sử dụng để chuyển các trang sách, tạp chí, bài báo từ bản in sang bản điện tử để lưu trữ cũng như phân phối. Nhưng OCR cũng chỉ là một phần mềm “bắt chước” khả năng đọc của con người, nếu như trang giấy có dấu hiệu sờn, cũ hoặc xuống cấp, OCR sẽ ngay lập tức không nhận diện được, dù một người bình thường có thể dễ dàng nhận ra chữ đó là gì.
Quay lại với reCAPTCHA, trong 2 chữ mà chương trình này “thách thức” người dùng, một chữ đã được nhận diện và lưu trong kho dữ liệu, một chữ còn lại sẽ đến từ danh sách các từ mà OCR không đọc được ở trên.
Nếu có ít nhất 6 người dùng cùng sử dụng một chữ để thay thế cho hình ảnh mà OCR không nhận diện được, reCAPTCHA sẽ xem nó như là một từ đã được “điện tử hóa” thành công.
reCAPTCHA “bán mình” như thế nào?

Với khả năng đọc chữ chính xác “gấp 6 lần người thường”, reCAPTCHA nhanh chóng ký hợp đồng với tờ báo danh tiếng New York Times để điện tử hóa tất cả bài viết cũ. Chỉ trong vài tháng hợp tác, reCAPTCHA đã dễ dàng điện tử hóa tất cả bài viết của New York Times trong vòng 20 năm trước khi có máy tính.
Và chỉ trong một năm hoạt động, hơn 440 triệu từ đã được điện tử hóa thành công, tương đương với gần 17.600 quyển sách!
Vào năm 2009, tức là chỉ 2 năm kể từ lúc thành lập, reCAPTCHA nhanh chóng được Google mua lại với một khoản tiền không được công bố (nhưng vài chuyên gia dự đoán giá trị ít nhất là 30 triệu USD).
Ngay sau khi thâu tóm, Google ngay lập tức sử dụng reCAPTCHA cho Google Books, biến đây trở thành thư viện điện tử lớn nhất thế giới chỉ sau vài năm.
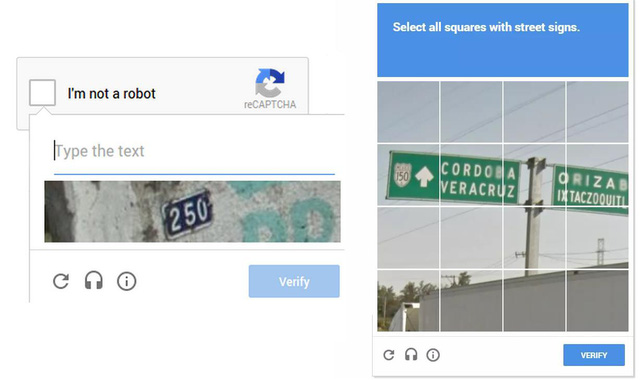
Không những thế, Google còn sử dụng reCAPTCHA cho nhiều mục đích khác, chẳng hạn như giải mã biển tên đường hay số nhà trên Google Maps Street View, phân biệt các phương tiện và biển hiệu giao thông cho dự án xe không người lái …
Có thể thấy rằng reCAPTCHA đã nhanh chóng chứng minh giá trị của mình và “hoàn vốn” nhanh chóng cho Google qua các ứng dụng trên.
reCAPTCHA là tấm gương của mô hình kinh doanh đơn giản mà hiệu quả. An ninh mạng và Nhận diện chữ viết là hai việc hoàn toàn không liên quan đến nhau, nhưng Luis đã kết nối được hai phạm trù này để “tận dụng” hàng triệu người trên khắp thế giới làm việc cho mình, tối ưu hóa nguồn lực của xã hội trước khi định nghĩa “kinh tế chia sẻ” được ra đời.
Làm sao để bắt chước reCAPTCHA?

Để “tận dụng nguồn lực” nhàn rỗi như reCAPTCHA, một mô hình mới cần phải thỏa mãn các điều kiện sau:
– Phục vụ một nhu cầu trực tuyến (Chẳng hạn như xác nhận người dùng không phải là robot).
– Phân phối hoàn toàn miễn phí.
– Thu thập nguồn lực đến từ khắp nơi trên thế giới để tạo ra một giải pháp mà công nghệ chưa đủ phát triển để giải quyết.
– Tìm cách bán giải pháp đó.
Sau khi thành công với reCAPTCHA, Luis đã thành lập Duolingo vào năm 2011, nhằm cung cấp một dịch vụ học ngôn ngữ hoàn toàn miễn phí và đi kèm là “giải pháp” dịch thuật chính xác hơn bất kỳ trí thông minh nhân tạo nào.
Nhưng cho đến nay, Duolingo dần chuyển qua mô hình “khuyến khích” người dùng đóng phí để học hiệu quả hơn cho thấy thành công của reCAPTCHA khó lặp lại hơn mọi người nghĩ.
Lê Thanh Sang – TTVN